Por Jorge Valverde-Rebaza, Alejandro Martín del Campo Huerta y Leonardo Cañete Sifuentes
Durante los meses más intensos de la elección presidencial mexicana de 2024, las redes sociales se convirtieron en un espacio donde las emociones políticas se expresaban con fuerza, rapidez y, muchas veces, con confrontación.
Comprender ese comportamiento es un ejercicio académico y es también una necesidad estratégica para analizar la democracia, entender fenómenos del ecosistema digital, anticipar patrones de polarización, detectar narrativas emergentes y evaluar cómo los ciudadanos reaccionan ante eventos electorales.
En este contexto, un equipo de profesores investigadores y estudiantes del Tecnológico de Monterrey desarrolló un estudio para analizar —en español— el sentimiento político. Esto lo hizo utilizando inteligencia artificial en mensajes de Facebook, Instagram, X y YouTube.
Emociones políticas según cada red social
Uno de los principales hallazgos del estudio es que las plataformas digitales no son homogéneas. Cada una tiene una “personalidad emocional” distinta que forma parte del debate público.
Buena parte de las opiniones políticas de los ciudadanos mexicanos se concentra en cuatro plataformas en las que se observa un comportamiento muy marcado: Instagram y Facebook son espacios con mayor proporción de mensajes positivos, mientras que X concentra el mayor volumen de reacciones negativas.
YouTube, por su parte, se caracteriza por un predominio de mensajes neutros, reflejando un consumo más contemplativo que argumentativo.
Esta heterogeneidad importa porque condiciona cómo se articulan los discursos y se propagan las emociones políticas. Un mismo mensaje puede generar apoyo entusiasta en Instagram o Facebook, rechazo abierto en X o relativa indiferencia en YouTube.
Desde la perspectiva electoral, esto sugiere que las campañas, los debates y los eventos coyunturales viajan por “carriles emocionales” diferentes, dependiendo de la plataforma, por lo que no basta con contar miles de impresiones o acumular “likes”: es necesario entender qué se siente y dónde.
La ‘nueva IA’ confronta a la IA tradicional
La contribución más sobresaliente del trabajo radica en su comparación sistemática entre modelos tradicionales de análisis de sentimiento y los grandes modelos de lenguaje (Large Language Models, LLMs) más avanzados disponibles en la actualidad.
Modelos como BERT, RoBERTa o su versión entrenada específicamente para español, BETO, representaron durante años un parteaguas en el procesamiento de lenguaje natural. Gracias a ellos se logró, por primera vez, capturar mejor el contexto de una oración y mejorar significativamente tareas como clasificación de textos, traducción o respuesta a preguntas. En su momento, estos modelos basados en la popular arquitectura de Transformers fueron el estado del arte y sentaron las bases de todo lo que vino después.
Sin embargo, al compararlos con los LLMs actuales, la brecha es clara. En nuestro estudio, se observó que los modelos tradicionales como BETO, RoBERTa o BERT-multilingüe son superados de manera contundente por LLMs como GPT-3.5, GPT-4o-mini, o1-mini o Llama-3. En prácticamente todas las métricas de evaluación consideradas, los LLMs muestran mejoras significativas.
Un aspecto clave del trabajo es cómo se usaron estos modelos. En configuración zero-shot, es decir, cuando el sistema intenta resolver una tarea solo a partir de una instrucción en lenguaje natural y sin ejemplos previos, el modelo recibe indicaciones como “clasifica este mensaje como positivo, negativo o neutro”.
En configuración few-shot, en cambio, además de la instrucción se incluyen algunos ejemplos ya clasificados dentro del mismo prompt, que sirven como guía para interpretar nuevos casos. El modelo no se reentrena: simplemente se orienta con contexto adicional. Incluso con tan pocos ejemplos, el salto en desempeño es notable.
El modelo GPT-4o-mini, especialmente bajo el esquema few-shot, alcanzó niveles de precisión superiores al 80 % en Facebook e Instagram y mantuvo resultados altamente competitivos, incluso en plataformas difíciles como X, donde predominan la ironía, la confrontación y mensajes breves cargados de emoción.
En contraste, los modelos tradicionales tienden a confundirse ante matices sutiles o ante la ambigüedad presente en debates políticos.
Estos hallazgos confirman que su era de dominio ya quedó atrás en este tipo de tareas de alta complejidad social.
Cómo interpretamos estos resultados
El incremento del rendimiento es un logro técnico y abre la puerta a nuevas posibilidades para estudiar la opinión pública.
Los LLMs lograron distinguir con mayor claridad cuándo un mensaje expresa rechazo genuino, cuándo se trata de apoyo explícito y cuándo un comentario aparentemente neutral encubre una postura implícita.
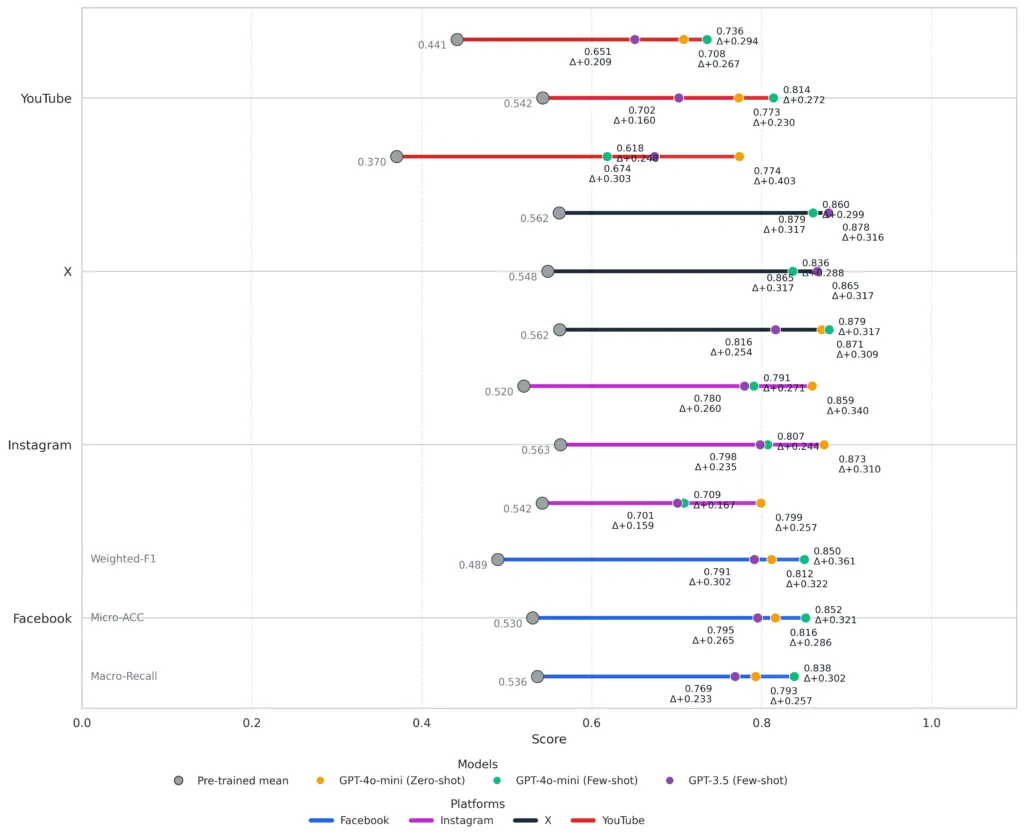
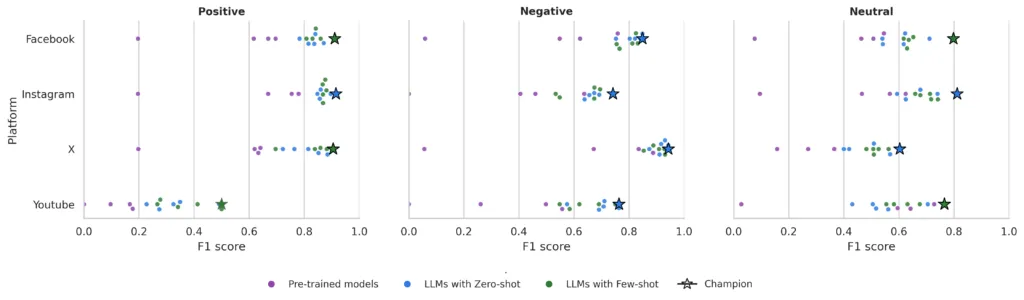
Cuando se identifica el “modelo campeón” para cada combinación de sentimiento (positivo, negativo, neutro) y plataforma, resulta que para el sentimiento positivo, GPT-4o-mini en modo few-shot domina con claridad en Facebook e Instagram, capturando expresiones explícitas de apoyo y entusiasmo. En X, en cambio, o1-mini se posiciona ligeramente mejor, lo que sugiere que modelos más ligeros también pueden adaptarse bien a discursos altamente polarizados.
En tanto que para el sentimiento negativo, GPT-4o-mini y GPT-3.5 en configuración few-shot muestran mejor capacidad para detectar mensajes adversariales, irónicos u hostiles, algo crucial en el análisis político.
La clase neutra sigue siendo la más desafiante: los resultados son más modestos y variables entre plataformas, lo que refleja la complejidad de interpretar mensajes aparentemente “fríos” que, muchas veces, esconden posturas veladas. En este mismo sentido también se abren nuevas preguntas para futuras investigaciones sobre potenciales sesgos de clasificación según el LLM que se use.
Estos hallazgos apuntan a una consideración importante: aunque los LLMs ya ofrecen un salto claro frente a la generación anterior de modelos, todavía hay terreno por explorar, especialmente en la manera en que el español expresa matices, dobles sentidos y referencias culturales que difieren fuertemente del inglés y, aún más, en asuntos tan coyunturales como pueden ser las elecciones de representantes políticos.
El futuro de las elecciones en México
El impacto de este avance es claro: con modelos predictivos más precisos, es posible monitorear, casi en tiempo real, cómo reacciona la ciudadanía ante acontecimientos políticos. Esto permite entender mejor la dinámica emocional que alimenta fenómenos como la polarización, la viralización de narrativas y la consolidación de comunidades digitales que pueden influir en percepciones electorales.
Además, abre la posibilidad de complementar las investigaciones alrededor de la propagación de desinformación y qué tipo de mensajes generan más resonancia emocional. Los LLMs, al capturar matices complejos, permiten identificar patrones emergentes que podrían pasar desapercibidos con herramientas tradicionales. Esta capacidad podría ser relevante para diseñar estrategias que reduzcan sesgos, detecten anomalías emocionales y contribuyan a campañas más responsables y transparentes.
Sin embargo, es necesario considerar que la mayoría de los estudios de referencia en análisis de sentimiento y en la evaluación de grandes modelos de lenguaje están desarrollados preponderantemente en inglés.
Por lo anterior, la presente investigación pone de relieve la urgencia y la necesidad de invertir y desarrollar modelos que atiendan a las particularidades del español, especialmente en contextos latinoamericanos, donde el lenguaje político incorpora humor, ironía, regionalismos y referencias locales que los modelos entrenados en inglés no capturan del todo.
Incrementar los sesgos lingüísticos y semánticos del idioma es un reto científico, pero también una oportunidad para impulsar el desarrollo tecnológico con justicia epistémica.

En contexto
Federico Castro-Zenteno, Efrén Jiménez-Garibaldy y Juliette Ceballos participaron en este proyecto desde que cursaban su estancia académica “Construyendo soluciones robustas basadas en LLMs”, aplicando métodos avanzados de IA a un problema real de impacto nacional que se concretó en un artículo científico de alto impacto.
El proyecto se desarrolló en colaboración con el Observatorio de Medios Digitales (OMD) del Tec de Monterrey, con la colaboración de Alejandro Martín del Campo, cuya infraestructura permitió acceder a datos reales y actualizados de la conversación pública. Esta alianza interdisciplinaria refuerza la idea de que entender el comportamiento electoral requiere tanto conocimientos técnicos como sensibilidad humana y social.
A cargo de Jorge Valverde-Rebaza y Leonardo Cañete-Sifuentes, el proyecto titulado “Pre-trained and Large Language Models for Sentiment Analysis of Spanish Social Media in the 2024 Mexican Elections” logró resultados reconocidos con el 3rd Best Paper Award en el XVII Hybrid Intelligent Systems (HIS), en el contexto del 24th Mexican International Conference on Artificial Intelligence (MICAI 2025), el evento de inteligencia artificial más importante de México.
.
Referencias
- M. Avalle, N. Di Marco, G. Etta, E. Sangiorgio, S. Alipour, A. Bonetti, L. Alvisi, A. Scala, A. Baronchelli, M. Cinelli, and W. Quattrociocchi. Persistent interaction pattern across social media platforms and over time. Nature, 628(8008):582–589, 2024.
- J. Cui, Z. Wang, S.-B. Ho, and E. Cambria. Survey on sentiment analysis: evolution of research methods and topics. Artificial Intelligence Review, 56(8):8469–8510, 2023.
- W. Zhang, Y. Deng, B. Liu, S. Pan, and L. Bing. Sentiment analysis in the era of large language models: A reality check. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 3881–3906. ACL, 2024.
.
Artículo base
J. Valverde-Rebaza, L. Cañete-Sifuentes, F. Castro-Zenteno, E. Jiménez-Garibaldy, J. Ceballos, and A. Martin del Campo. Pre-trained and Large Language Models for Sentiment Analysis of Spanish Social Media in the 2024 Mexican Elections. In Proc. of the 24th Mexican International Conference on Artificial Intelligence. Advances in Computational Intelligence. (MICAI 2025 International Workshops). Lecture Notes in Computer Science, vol. 16264, Springer, 2026.
.
Autores
Jorge Valverde-Rebaza. Es profesor de la Escuela de Ingeniería y Ciencias del Tec de Monterrey. Doctor y Maestro en Computación y Matemática Computacional por la Universidad de São Paulo (USP), Brasil. Realizó estancias de investigación en Francia y Portugal. Sus áreas de interés son ciencia de datos, análisis de datos sociales y procesamiento de lenguaje natural (PLN) y aprendizaje de máquinas. Su trabajo se centra en sistemas basados en grandes modelos de lenguaje (LLMs) aplicados a problemas reales y en la construcción de productos de analítica con foco en confiabilidad, costos, latencia y privacidad.
Alejandro Martín del Campo Huerta. Es líder del Observatorio de Medios Digitales, de la Escuela de Humanidades y Educación, del Tec de Monterrey. Es Director de la iniciativa de Humanidades Digitales en el Tecnológico de Monterrey. Con experiencia profesional en medios de comunicación y opinión pública, su trayectoria comprende la investigación de audiencias, programación de canales de televisión, así como la producción de noticiarios. Sus líneas de investigación se encuentran en la comunicación y participación ciudadana con la intersección de tecnologías emergentes. Actualmente es consejero en casas editoriales.
Leonardo Cañete Sifuentes. Es profesor de la Escuela de Ingeniería y Ciencias del Tec de Monterrey. Obtuvo su Doctorado en Ciencias Computacionales en 2022 por parte del Tecnológico de Monterrey, en donde actualmente es profesor de tiempo completo enfocado en ciencias computacionales, ciencia de datos y aprendizaje automático. Sus principales intereses de investigación son los clasificadores interpretables, problemas de desbalance de clases y los grandes modelos de lenguaje (LLMs).