
Sports are physical activities that human beings do mainly for recreational purposes and/or to improve their physical condition. Throughout the history of mankind, sports have had a big influence on culture and the building of a national identity. They also have a positive impact on a country’s development in areas such as education, the economy, and public health.
Due to the amount of attention that certain sports disciplines receive, they have become one of the world’s biggest businesses and have proven to be an important part of economic growth. Of all the sports that exist, many experts agree that soccer is the most popular in the world as it triggers large movements of money through bets, sponsorships, match attendance, sale of jerseys, accessories, etc. This is why there has been so much interest in creating predictive and statistical models.
In addition, the large amount of information available, such as match results, investments made, and player characteristics, makes it possible to find mechanisms that provide competitive advantages.
The proposal
There are several factors that have an impact on the outcome of a soccer match, such as team and/or player morale and skills, training strategy, and equipment. All this makes predicting the outcome of a match complex, even for experts in the field.
It also generates interesting research questions when we want to obtain a general prediction model that can be applied to any soccer match. For example: What impact do the rules of each league have on the outcome? Is it the same as predicting a regular league match, a league tournament match, or an international tournament? How possible is it to get a good prediction by knowing only the results of previous matches?
To answer these questions, we set out to predict soccer match results from 52 leagues around the world using about 200,000 previous match results from regular league matches (not including league tournaments). The same prediction model would then be used to predict the group stage of the Soccer World Cup organized by FIFA.
Construction of the model is based on Machine Learning. This discipline from the field of Artificial Intelligence creates systems that learn automatically. Learning in this context means identifying complex patterns among millions of data points. Through the identification of patterns, it is possible to build predictive or classification models.
In this proposal, we use a model based on two axes. The first is a Bayesian model based on the ranking of each team, and the second is based on the shared history of the teams in question.
The ranking
Teams are ranked after the season is over. The FIFA ranking method is used for this purpose, combining the total number of goals scored and conceded during the entire season.
When a new team enters the league, this can penalize its ranking. The method chosen to balance the score is to take into account the history of points by the veteran teams. Thus, a veteran team’s score is composed of 20% of its previous score and 80% of its current score.
The model
The Bayesian model uses the ranking position of each team in competition to obtain a probability of success or failure. Subsequently, using random variables generated with a triangular distribution, an adjustment measurement is obtained to recalculate the probability of winning or losing. When the difference in team odds is less than 10%, a tie is declared.
The prediction also takes into account the shared history of competing teams. Analysis of historical data detected that teams which consistently face each other in some leagues develop patterns of results that are independent of the position they are ranked in.
Thus, the full model considers this pattern of behavior in conjunction with the team’s ranking to determine a probability of winning, losing, or drawing a match.
The forecast
A database of approximately 200,000 soccer match results from 52 leagues around the world was used to make the regular league forecast. The database contains information on the season, league, date of the match, home team, away team, and the result of the match. A prediction was made for the day of the match to be held for each league after the last date recorded in the database.
The FIFA score list of each qualified team in the World Cup was used to make the forecast for the World Cup, as well as information on teams by group and date of the matches. A forecast was made for the group elimination stage, in which three rounds of matches are played between members of each group. The two teams with the best score in each group qualify for the next stage.
The results
A Ranked Probability Score (RPS) was used to measure the effectiveness of the prediction. This measurement penalizes forecasts more severely when their probabilities are further from the actual outcome. The value obtained with this measurement is within the range of 0-1, with zero being the most desired value.
Another measurement used is the absolute accuracy of the forecast, verifying the percentage of success in the prediction with this measurement.
The following graph shows the prediction results by league, with the average RPS obtained being 0.2620, while the accuracy is 46%. These results are competitive when compared to the state of the art. The graph shows the average result obtained per league, with the size of the circle indicating the number of predictions made. As can be seen, most of the results tend to be in the upper left portion of the graph, indicating greater accuracy and little prediction error.
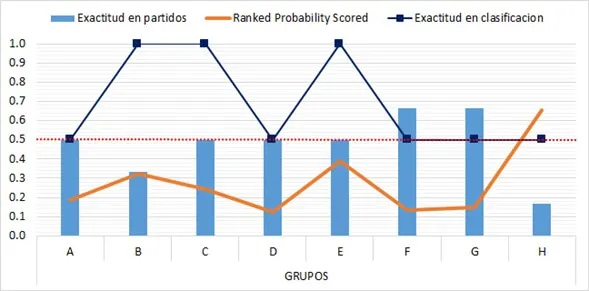
World Cup results are shown in the following graph. The bars indicate the average accuracy obtained in match predictions for the three rounds of matches per group, with an average result of 0.48. The orange line indicates the RPS obtained for match prediction, with an average of 0.276. Finally, the blue line indicates the accuracy of the teams selected for phase 2, with an average of 0.68.
In conclusion
The main motivation for this work is the opportunity to test forecasting models in a subject as popular as soccer. Despite a lack of knowledge about soccer in general, we were able to first understand the challenge and then develop a predictive model that was easy to implement.
Each league is driven by different motivations that influence the outcome of a match. This can make it difficult to recognize patterns when only the outcome of previous matches is known. However, the model allows us to recognize patterns useful for prediction.
In this development, most of the time was invested in defining the best way to classify and accommodate the data and programming the procedures, trying to make them as efficient as possible.
The proposed methodology is simply one instance of a more general framework, applied here to soccer. Although the framework can, in principle, be adapted to a wide range of sports domains, it cannot be used in domains with insufficient data.
Another approach to explore in the future is a knowledge-based system. This generally requires relatively good quality knowledge, whereas most machine learning systems rely on a large amount of data to obtain good predictions.
It is important to understand that each soccer league behaves according to a particular environment. Therefore, a better prediction model should include particular characteristics of the match being played, such as the importance of the match, which could help improve prediction accuracy.
Future work in this area includes the development of a model that attempts to predict the match score, more advanced techniques, and the use of different parameters to assess the quality of the outcome.
The author
Laura Hervert Escobar holds a degree in Industrial Engineering from the National Polytechnic Institute. She has a Ph.D. in Systems and Engineering Management from Texas Tech University and a Ph.D. in Engineering Sciences from Tecnológico de Monterrey, where she currently works as a postdoctoral researcher. Her research includes the development, analysis, and implementation of metaheuristic techniques to solve complex real-life combinatorial problems with various objectives. laura.hervert@itesm.mx