By Jorge Valverde-Rebaza, Alejandro Martín del Campo Huerta and Leonardo Cañete Sifuentes
During the most intense months of Mexico’s 2024 presidential race, social media became a space where political emotions were expressed forcefully, rapidly, and often confrontationally.
Understanding that behavior is not only an academic exercise, it is also a strategic necessity. It helps analyze democratic dynamics, make sense of digital ecosystem trends, anticipate patterns of polarization, identify emerging narratives, and assess how citizens respond to electoral events.
Against this backdrop, a team of faculty researchers and students at Tecnológico de Monterrey conducted a study to analyze political sentiment—in Spanish—using artificial intelligence across messages posted on Facebook, Instagram, X, and YouTube.
Political emotions by platform
One of the study’s main findings is that digital platforms are far from homogeneous. Each has a distinct “emotional personality” that shapes public debate.
A large share of Mexican users’ political opinions is concentrated on four platforms, where clear behavioral patterns emerge: Instagram and Facebook tend to host a higher proportion of positive messages, while X concentrates the largest volume of negative reactions.
YouTube, for its part, is characterized by a predominance of neutral messages, reflecting a more observational than argumentative mode of engagement.
This heterogeneity matters because it conditions how narratives are framed and how political emotions spread. The same message can generate enthusiastic support on Instagram or Facebook, open rejection on X, or relative indifference on YouTube.
From an electoral standpoint, this suggests that campaigns, debates, and major political moments travel along different “emotional lanes” depending on the platform. Simply tallying impressions or accumulating likes is not enough; what matters is understanding how people feel—and where.
The ‘new AI’ challenges traditional models
The study’s most notable contribution lies in its systematic comparison between traditional sentiment analysis models and the most advanced large language models (LLMs) available today.
Models such as BERT, RoBERTa, and their Spanish-trained counterpart BETO marked a turning point in natural language processing. For the first time, they made it possible to capture sentence-level context better and significantly improve tasks such as text classification, translation, and question answering. Built on the now-ubiquitous Transformer architecture, these models once represented the state of the art and laid the groundwork for everything that followed.
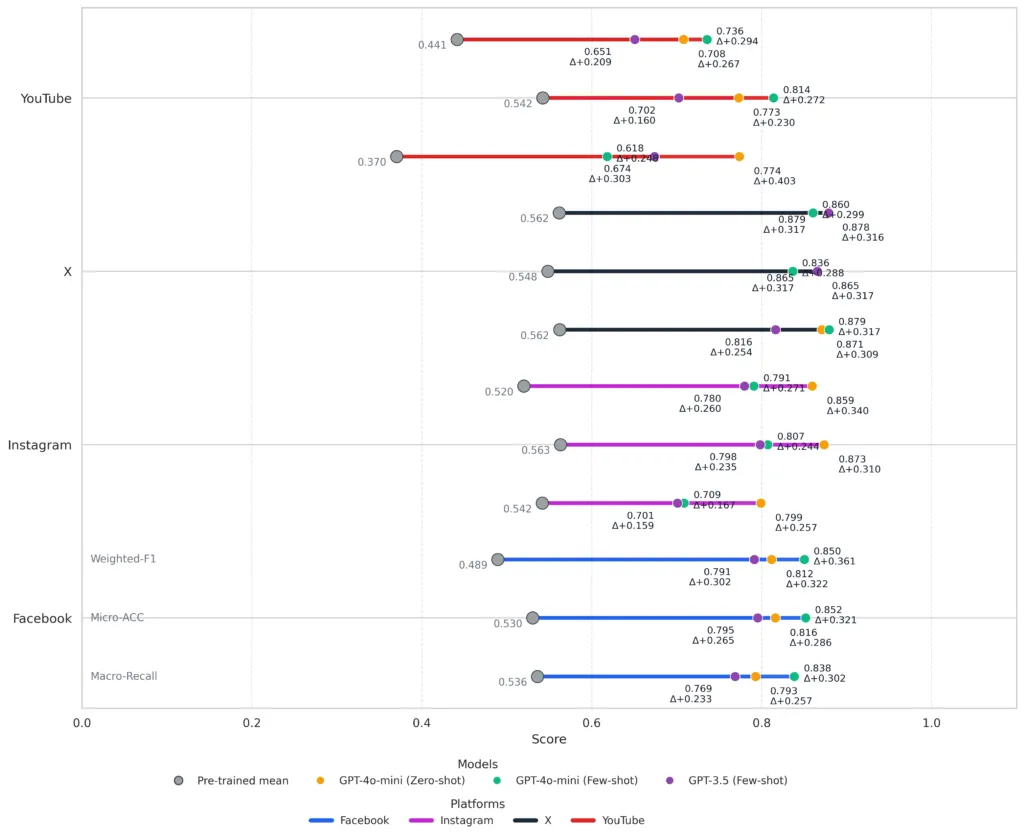
But compared with today’s LLMs, the gap is clear. The study found that newer systems like GPT-3.5, GPT-4o-mini, o1-mini, and Llama-3 decisively outperform traditional models such as BETO, RoBERTa, and multilingual BERT. Across virtually every evaluation metric, LLMs delivered significant gains.
A key aspect of the study is how these models were used. In a zero-shot setting—where the system attempts to complete a task based solely on a natural-language instruction, without prior examples—the model might be prompted with something like: “Classify this message as positive, negative, or neutral.”
In a few-shot setting, by contrast, the prompt includes a small number of labeled examples alongside the instruction, guiding the model in interpreting new cases. The model is not retrained; it is simply steered with additional context. Even with just a handful of examples, the performance gains are substantial.
GPT-4o-mini, particularly under the few-shot approach, achieved accuracy levels above 80 percent on Facebook and Instagram, while maintaining highly competitive results on more challenging platforms such as X, where irony, confrontation, and emotionally charged brevity are common.
By contrast, traditional models tend to struggle with subtle nuances and the ambiguity often present in political discourse.
These findings suggest that, for this class of socially complex tasks, the era of traditional models has effectively come to an end.
How to interpret these results
The performance gains are not just a technical milestone; they open the door to new ways of studying public opinion.
LLMs were better able to distinguish when a message expressed genuine rejection, when it conveyed explicit support, and when a seemingly neutral comment masked an implicit stance.
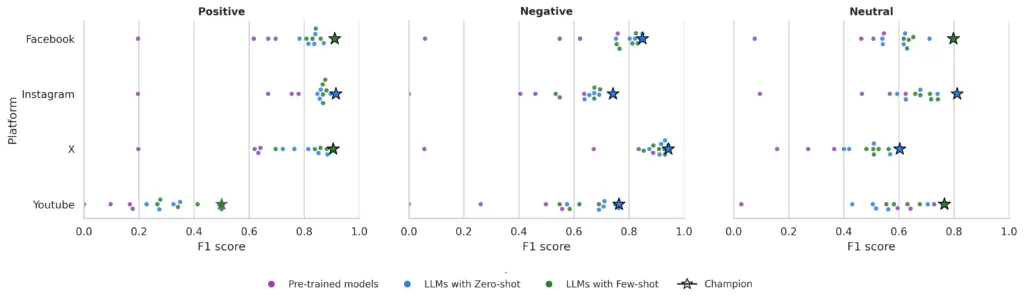
When the “top-performing model” is identified for each combination of sentiment (positive, negative, neutral) and platform, a clear pattern emerges. For positive sentiment, GPT-4o-mini in few-shot mode stands out on Facebook and Instagram, effectively capturing explicit expressions of support and enthusiasm. On X, however, o1-mini performs slightly better, suggesting that lighter models can also adapt well to highly polarized discourse.
For negative sentiment, GPT-4o-mini and GPT-3.5 in few-shot settings show a stronger ability to detect adversarial, ironic, or hostile messages—an essential capability for political analysis.
Neutral sentiment remains the most challenging category. Results are more modest and vary across platforms, underscoring the difficulty of interpreting seemingly “flat” messages that often conceal implicit positions. This also raises new questions for future research, particularly around potential classification biases depending on the LLM used.
Taken together, these findings point to an important conclusion: while LLMs represent a clear leap forward over the previous generation of models, there is still ground to cover—especially in how Spanish conveys nuance, double meanings, and cultural references that differ significantly from English, and even more so in time-sensitive contexts such as electoral politics.
The Future of Elections in Mexico
The implications of this advance are clear: with more accurate predictive models, it is now possible to monitor—almost in real time—how citizens react to political events. This makes it easier to understand the emotional dynamics that drive phenomena such as polarization, the viral spread of narratives, and the formation of digital communities that can shape electoral perceptions.
It also opens the door to complementing research on the spread of disinformation and identifying which types of messages generate the strongest emotional resonance. By capturing complex nuances, LLMs make it possible to detect emerging patterns that traditional tools might miss. That capability could prove valuable in designing strategies to reduce bias, flag emotional anomalies, and support more responsible, transparent campaigns.
At the same time, it is important to recognize that most benchmark studies in sentiment analysis and large language model evaluation are still conducted primarily in English.
Against this backdrop, this research underscores the urgency of investing in and developing models that account for the particularities of Spanish—especially in Latin American contexts, where political language is shaped by humor, irony, regionalisms, and local references that English-trained models do not fully capture.
Addressing linguistic and semantic biases in the language is both a scientific challenge and an opportunity to advance technological development with greater epistemic equity.

Inside the Project
Federico Castro-Zenteno, Efrén Jiménez-Garibaldy, and Juliette Ceballos took part in this project while completing their academic residency, “Building Robust Solutions Based on LLMs,” applying advanced AI methods to a real-world problem of national relevance that ultimately resulted in a high-impact scientific publication.
The project was developed in collaboration with Tecnológico de Monterrey’s Digital Media Observatory (OMD), with support from Alejandro Martín del Campo, whose infrastructure made it possible to access real-time data from the public conversation. This interdisciplinary partnership reinforces the idea that understanding electoral behavior requires both technical expertise and social and human insight.
Led by Jorge Valverde-Rebaza and Leonardo Cañete-Sifuentes, the project—titled “Pre-trained and Large Language Models for Sentiment Analysis of Spanish Social Media in the 2024 Mexican Elections”—earned the 3rd Best Paper Award at the XVII Hybrid Intelligent Systems (HIS), held as part of the 24th Mexican International Conference on Artificial Intelligence (MICAI 2025), the country’s leading AI conference.
References
- M. Avalle, N. Di Marco, G. Etta, E. Sangiorgio, S. Alipour, A. Bonetti, L. Alvisi, A. Scala, A. Baronchelli, M. Cinelli and W. Quattrociocchi. Persistent interaction patterns across social media platforms and over time. Nature, 628(8008):582–589, 2024.
- J. Cui, Z. Wang, S.-B. Ho, and E. Cambria. Survey on sentiment analysis: evolution of research methods and topics. Artificial Intelligence Review, 56(8):8469–8510, 2023.
- W. Zhang, Y. Deng, B. Liu, S. Pan, and L. Bing. Sentiment analysis in the era of large language models: A reality check. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 3881–3906. ACL, 2024.
.
Key article
J. Valverde-Rebaza, L. Cañete-Sifuentes, F. Castro-Zenteno, E. Jiménez-Garibaldy, J. Ceballos, and A. Martin del Campo. Pre-trained and Large Language Models for Sentiment Analysis of Spanish Social Media in the 2024 Mexican Elections. In Proc. of the 24th Mexican International Conference on Artificial Intelligence. Advances in Computational Intelligence. (MICAI 2025 International Workshops). Lecture Notes in Computer Science, vol. 16264, Springer, 2026.
.
Authors
Jorge Valverde-Rebaza. Professor in the School of Engineering and Sciences at Tecnológico de Monterrey. He holds a Ph.D. and M.Sc. in Computer Science and Computational Mathematics from the University of São Paulo (USP), Brazil, and has conducted research stays in France and Portugal. His work focuses on data science, social data analysis, and natural language processing (NLP), as well as machine learning. He specializes in LLM-based systems applied to real-world problems and in building analytics products with an emphasis on reliability, cost, latency, and privacy.
Alejandro Martín del Campo Huerta. He leads the Digital Media Observatory at Tecnológico de Monterrey’s School of Humanities and Education and directs the university’s Digital Humanities initiative. With a professional background in media and public opinion, his experience spans audience research, television programming, and news production. His research focuses on communication and civic engagement at the intersection of emerging technologies. He currently serves as an advisor to publishing organizations.
Leonardo Cañete Sifuentes. He is a professor in the School of Engineering and Sciences at Tecnológico de Monterrey. He earned his Ph.D. in Computer Science from the institution in 2022, where he now serves as a full-time faculty member specializing in computer science, data science, and machine learning. His research interests include interpretable classifiers, class imbalance problems, and large language models (LLMs).